Greetings programs!
I’ve been quite surprised by the response to the news that I passed the lab. I suspect a lot of it is due to my friend Katherine who has a sizeable following on account of her excellent blog. If you haven’t checked it out, you should!
Anyhow, from all my new friends, I received a lot of questions. This post is intended to answer them in one place, as well as supply some additional context, and share some of the key resources that I used in my preparation.
The big question, Why?
For large undertaking like this, you need to have a pretty strong reason, or reasons. It’s a sizeable commitment and when things get really hard, you’re likely to give up if there’s not a good reason for doing it.
In my case there were several reasons. Listed in no particular order:
- Increase my knowledge level. I like to have a deep understanding of what I’m working with.
- Increase my income earning capability
- Prove to myself that passing Route/Switch wasn’t a fluke; that I could put my mind to a goal of similar scope and do it again in an area where I have less background.
- I enjoy the topics. These toys are a **lot** of fun to play with.
Having seem mine, hopefully it will help you work with defining yours.
The commitment required
Let’s take a realistic assessment of the level of effort required. Understand this is going to specific to the individual based upon:
- The existing expertise brought to the starting line
- How much of the blueprint covers work performed in day job
- Ability to purchase quality training materials
- Quality of the structures used to facilitate learning process
- Consistent application of effort (i.e. not engaging in distractions during study time)
- Capacity to absorb and process the information
In my case, I was already familiar with much of the VPN technology and I knew my way around ASA firewalls and firepower, all of which I implement and support in my day job. Additionally I had recently completed CCIE Route/Switch, so I knew how to structure information for later retrieval and how to establish a sustainable study routine. However I was a complete newbie to ISE and Cisco wireless networking.
With all that, it took me approximately 19 months and two attempts, studying an average of 20 hours a week, for a total effort of somewhere around 1600-1700 hours. I reckon the range for the vast majority of candidates would fall somewhere between 1200 and 2500 hours, presuming they average 20 hours a week of quality study time without significant gaps.
Support and buy in from your family
Consider this: You’re already employed with full time job and you have adult obligations to maintain. When you start studying 20+ hours a week, your wife and your kids (if you have them) are going to feel your absence, and it’s not going to be easy for them. There needs to be relevant reasons for them as well because they are going to sacrifice alongside you. It’s a good idea to talk to them and ensure they have a crystal clear understanding of what the next 18 to 24 months going to be like, and get their buy-in. This is not worth losing your family over!
I strongly recommend taking one day off a week to spend that quality time with your family. That may not be possible in your final push, but that’s just the end phase. This is a marathon not a sprint.
Establishing milestones
One thing that derails a lot of candidates is lacking a clear path to the end goal. You need a sense of urgency and momentum. It’s easy to get lost in the technical deep dives (especially with the larger topics like VPN and ISE), but it’s important to keep moving.
It’s ok to make adjustments as you go along, and there will be setbacks. The idea is to have something to help you stay on track so at some point you’ve got your ass planted in a seat at a lab location and you’re making it happen.
Example high level outline
Months 1-3: Pass one through the blueprint
- Focus on basics
- 70% theory 30% lab
Months 4-7: Pass two through the blueprint
- Go deeper into the details and advanced use cases, read rfc and advanced docs.
- 50% theory 50% lab
Months 8-9: Prepare for written
- Heavy on theory and facts
- Study written only topics
- 80% theory 20% lab
End of month 9: take written exam
Months 10-12: Pass three through the blueprint
- Repeat deep dive, with more emphasis on hands on
- focus mostly on VPN and ISE
- 30% theory 70% lab
Months 13-14: multi-topic labs
- No more deep dives
- Combine multiple technologies in each labbing session
- get used to shifting gears
- Wean off cli. Build all config in notepad
- 20% theory 80% lab
Schedule lab for 90 days out
Months 15-17: final push for lab
- Lab every topic on blueprint during the week
- Lab all topics in one sitting 1x/week
- all config in notepad
- speed and accuracy paramount
- Stop using debugs
- Time all exercises
- include verification in time
- Get friend to break your labs for troubleshooting practice
- 10% review, 90% lab
End of month 17: First attempt
The battle of memory
Setting up your notebook and files
In the beginning, you’re not going to have much to look at in terms of accumulated knowledge. That will gradually change. It’s a really good idea to set up a system at the beginning; a whole lot easier before you’ve accumulated a bunch of stuff.
My preference these days is OneNote, but other tools will of course work fine. Heck even an old 3 ring binder can do the job if that’s what you’re into.
Converting the blueprint into something more practical
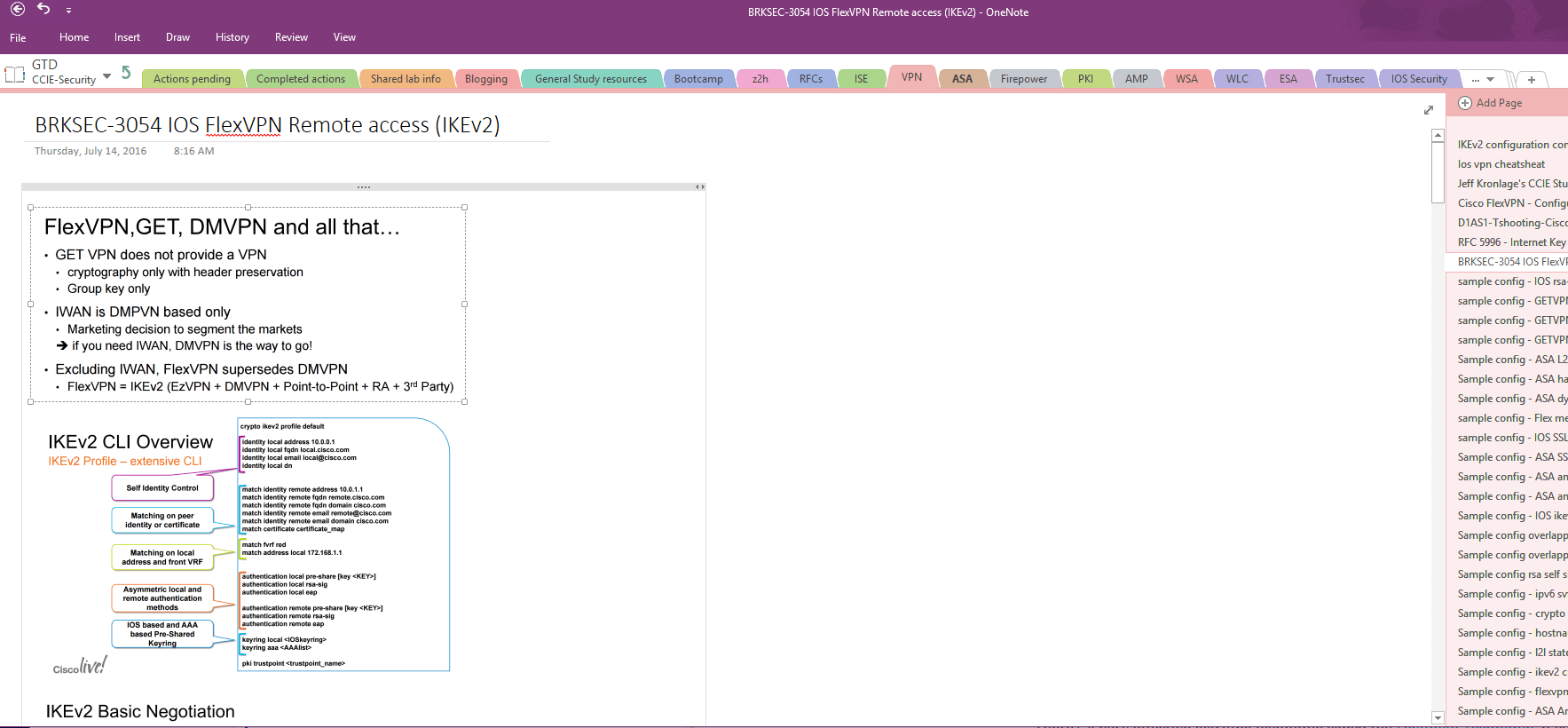
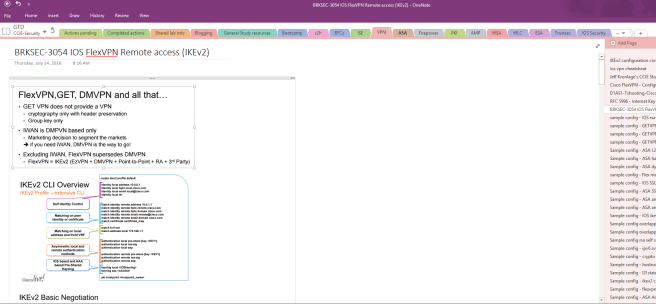
When your setting up your notebook, the first intuition might be to mirror the blueprint. i.e. a tab called 1.0 Perimeter Security and Intrusion Protection. Here’s my suggestion: Organize by product and technology, with additional tabs for unprocessed notes, running and completed tasks, general info, classes taken, etc. Here’s a screenshot of my tab list for example:
Should you start a blog?
There’s a very effective learning technique called the Feynman Technique. It consists of 5 steps.
- Write down the name of a concept
- Write out an explanation of the concept as you understand it in plain English.
- Review what you’ve written, study the gaps you’ve discovered in your knowledge. Update your explanation
- Review your explanation a final time and look for ways to simplify and improve clarity.
- Share this explanation with someone.
It really does work.
Blogging is a perfect vehicle for this sort of thing. But here’s the rub: Blogging is a skill that takes effort to develop. In my own experience, my early posts took hours to write and I just about gave up on it due to the amount of time that it took. But as I kept doing it, I got more efficient, and ultimately I found it gave a good return on the time invested.
It’s not a requirement of course. It’s just a tool, and there lots of other useful tools to choose from.
Written prep and fact memorization Tools
The written covers things you’ll see in the lab, but it also stresses blueprint items that aren’t testable in hands on environments, such as knowledge about theory, standards and operations, and emerging technologies.
You’ll need to have a lot of facts at your recall for the written, so you’re going to have to do a lot of memorization. That means good old spaced repetition.
The two products that I’ve used to aid in memorization are Anki and Supermemo. I have a personal preference for supermemo, but it’s a quirky program with a learning curve. Anki is much easier to pick up and start using. Either one of these tools are a good aid for the memorization grind that’s part and parcel of passing a CCIE written exam.
Gathering learning resources
This will be an ever expanding list as you get deeper into your studies, but before you start, it makes sense to have some material lined up to take you on that first tour though the blueprint. As there is not a one stop guide for the security track, this first step can take a little bit of time. You should have your study material for the first six to 9 months lined up before you dive in order to ensure you make productive use of your time. The resource list near the end of this post Will hopefully make a good starting point.
Labbing equipment
You will want to invest in some equipment for this track. If you’re serious about doing this, it’s the best way. Yes you can do quite a bit on GN3 and EVE-NG, but you’re going to want to have a lot of seat time with the switch and the firewalls, and you’re going to want large topologies that include resource hungry appliances. A good strategy is to pool your resources with a couple of other people and host your gear in a cheap colo.
This is the lab gear that I recommend:
- Server: EXSi host with 128gb ram, 12 cores, 1tb disk
- Switch: Catalyst 3650 or 3850 is best, a 3750x is a good budget option
- AP: 3602i or similar
- IP Phone: Cisco 7965G
- Firewall: 2xASA 5512-X with clustering enabled.
- Optional gear for COLO:
- Terminal Server (I Prefer OpenGear IM series: not cheapest but quite secure)
- Edge firewall: ASA 5506x
Equipment thoughts and notes
There’s lots of good deals on older 1u rack mount servers on ebay, that’s easy information to research. If you can afford more than 128gb of ram, go for it. You’ll use all of it once you start labbing larger toplogies.
When shopping for switches on ebay avoid switches with the LAN Base image, as IP Base is the minimum version required to use most features on the blueprint. Also, it never hurts to check the Trustsec Compatibility Matrix for the specific part you’re looking at buying.
Yes, you want to drop the coin on a pair of ASAs. Just do it. You don’t have to spring for the x series, but you do need multicontext and clustering, and you need to be able to run version 9.2 of the ASA software, those are your minimums.
My labbing partner and I started out with a cheap terminal server and the darn thing kept getting DOSed, so we dropped 400 bucks on an older Opengear terminal server, and that thing is bulletproof. Worth the extra money for out of band access to your gear.
Most COLOs, even budget ones, have remote hands to power cycle things for you if they get locked up. But if you’re not comfortable with that, hooking up a PDU like an old APC AP7931 to your terminal controller will work. I use one of these for my home rack and they’re great.
About software and platform versions
You want to match the versions on the blueprint as much as you can. Where it’s not realistic or a hassle to do so; I strongly urge you to check your syntax and configs against the lab version periodically if possible.
Personal experience: I my environment I labbed on the newer version of the CSR1kv image that has the 1mb/sec throughput limitation in demo mode. That’s great, but some of my configuration speed optimizations blew up on lab day. That repeated in several areas, including differences between the 3750x in my lab and the 3850 in the actual lab.
Bottom line: It’s a lot of money and stress to go sit the lab, and when the clock is ticking and you’re running into unexpected platform and software issues, the little bit of money you saved on that screaming ebay deal for an older part will be long forgotten.
About licensing the appliances in your lab.
Most of stuff is not a problem, you can run them on demo licenses. The exceptions are NGIPS WSA and ESA which are a pain. If you don’t work for a partner or Cisco, your local Cisco SE should be able to get you 3 month licenses for those appliances to assist with lab prep.
Establishing the daily routine
This is a critical item. It’s just like a fitness routine. Consistency is everything. You’re not going to be able skip studying during the week and binge on weekends expecting quality results. It just doesn’t work that way.
In my view, the bare minimum do to this in 18 months is 20 hours a week. That’s 20 focused hours without distractions.
There are going to be days when you *really* don’t want to study. Embrace the suck my friend, and just do it anyway.
Suggested Schedule
- 3-4 hours a day Monday through Friday
- 8 hours Saturday
- Sunday off
If you stick to that week in and week out, you will make good steady progress.
One thing that really helped me is a tool called tomato timer. The idea is for 25 minutes you’re hyper focused. Then you take 5 minutes off. Then 25 minutes on again. It really helps with procrastination and the urge to check your twitter feed and all that.
Responding when life gets in the way
FACT: Things are going to happen that are out of your control. You’re probably going to get pulled away from your studies for a week or two here and there.
Try to at least read a little bit and stay mentally engaged on some level every day until the clouds part and you’re able to get back on the grind again. Main thing is don’t let a short break turn into a long one; it happens very easily and you’ll be upset with yourself as you have to retrace your steps to get back to where your were in your progress.
Resource List:
Here’s a list of learning resources that I found to be particularly helpful. (Not including obvious things like product documentation).
Books
Videos
Instructor led Training
Workbooks
DCloud Labs
- Security Everywhere
- IPSEC VPN troubleshooting
- Web Security Appliance Lab v1
Cisco Live Sessions
Cisco ISE community
Closing thoughts
I hope this answered some of your questions and gave you a sense of a path to get to the CCIE Security lab. I really enjoyed reliving all the memories creating this post triggered. It’s been quite an adventure. 🙂
Best regards, and may you care for yourself with ease,
-s