Today’s post is an excerpt from my CCIE Security notes, and it has a useful table of Diffie Hellman groups, which you can use as a job aid in IPSEC VPN designs. I Hope you find it useful.
About Diffie Hellman
The key bit of magic that makes IKE (Internet Key Exchange) possible is Diffie-Hellman. Diffie-Hellman allows anonymous entities to calculate a shared secret that can’t be discovered by a third party listening to the exchange. What’s amazing about it is the peers are able to do this using two different passwords that they keep private and never exchange. DH is one of the earliest examples of Public Key Cryptography.
Key points
Diffie-Hellman does not provide authentication. It’s used to assist in creating a secure channel for authentication
Diffie-Hellman does not provide encryption. It provides the keying material for encryption.
Diffie-Hellman is used for control plane functions only.
Operations
At a high level it works like this:
If side a and side b use the same generator and modulus, resulting values from step 5 and 6 should be the same. This shared key is used as an input to the negotiated encryption algorithm.
In the case of Diffie-Hellman The generator and Prime (g,p) are predefined values (defined in a number of different RFCs) which are referenced as Diffie-hellman groups. The larger the Generator and Prime are, the more difficult it is to break. As computational power has increased substantially since the first DH groups were defined, the old groups are no longer safe to use.
The following Table lists the Diffie-Hellman Groups:
Diffie Hellman Groups
*NGE refers to Cisco Next Generation Encryption, which is the vendors set of recommended ciphersuites.
*NSA Suite B refers to the United States the National Security Agency’s published list of list of interoperable modern cryptographic standards.
I recently took a course on critical thinking, and I would like to share a couple of ideas about working with emotions and using them as a diagnostic tool.
Thinking about thinking
Think—>Feel—>Want
If we look at how the human mind works, we can simplify the order of operations down to three steps:
Thinking
Feeling
Wanting
Credit: ‘Critical Thinking’ By Richard Paul and Linda Elder
The implications of this are rather profound. If our emotions are driven by our thoughts, it follows that we can change our emotional experience of the world by changing our thinking.
It further follows that if we’re having emotions that don’t seem particularly helpful, such as a generally negative outlook, than the key is to examine the thinking that led to those feelings. Which brings us to the second idea.
Check your assumptions
Assumptions represent our implicit beliefs about the world, and they are usually subconscious in nature. We use assumptions to rapidly interpret and make decisions. This pretty helpful in a situation where we need to react immediately such as taking evasive action to avoid a car accident. They are less helpful when they are used to make judgments based on a perspective or situation that’s no longer relevant, such as being an adult instead of a child.
Credit: ‘Critical Thinking’ By Richard Paul and Linda Elder
If we want to evaluate our thinking, and we know that our thinking is driven by subconscious assumptions, we have to find a way to bring those assumptions to the surface so we can take a look at them. How can we do that? We can ask questions!
Questions we might ask:
What is the goal of this thinking? What problem am I trying to solve?
What questions am I trying to answer?
What facts do I have?
What perspective am I looking at this from?
Putting it together
Once we’ve brought these assumptions to the surface, we can decide if they’re relevant and make sense. If they are, we now have an explicit reason and supporting argument to underpin our thinking.
If our assumptions don’t hold up, and we have no good supporting facts or reasons behind our thinking, then we can go back and look at the purpose of the thinking and see if it makes sense to reframe things in a way that can be supported by facts or reasons.
Maybe I’m just tired or hungry.
Maybe it’s something I can’t control and I have to let go.
Maybe it’s an unhealthy a situation I need to extract myself from
Maybe I need to look at this from a different perspective
Wrap up
Welp, that’s it for today. I hope was interesting and/or useful, and I’ll see you around.
I believe it’s a safe assumption that the current crop of budding network engineers are being indoctrinated with the notion that if they don’t 100% automate all the things, their jobs and careers will be at risk. My friend Daniel Dibb deserves ample credit for repeatedly asking the question “What happens when we subsequently end up with a generation of automation engineers who don’t understand networking?”.
Yesterday morning I was drinking coffee, scrolling through my Twitter feed, when I came across a thread where Marko Milivojevićposted a link to a youtube video of American Airlines Captain Warren Van Der Burgh, delivering a talk in 1997 called Children of the Magenta Line. The context is lessons learned from a rash of airline crashes caused by flight crews becoming too dependent on automation.
If you are an infrastructure engineer, or you manage infrastructure engineers, this video is worth 25 minutes of your time.
There are two quotes that stand out from this Video:
We are Pilots and Captains, not Automation Managers
You’ve got to pick the appropriate level of automation for the task at hand
In googling the name of the video, I came across this article which had a quote from William Langewiesche which also illustrates a fundamental problem with over reliance on automation:
“We appear to be locked into a cycle in which automation begets the erosion of skills or the lack of skills in the first place and this then begets more automation.”
Let’s learn from the Airline industry and not repeat their mistakes.
Flock of birds wheeling around a statue of the barefoot mailman
Over the last week or so I’ve been working on an Infrastructure as code Azure Hybrid cloud deployment, based on the Azure Spoke and Hub reference topology.
Here’s a link to the Azure Deployment Guide for the CSR1kv, which has some really interesting tidbits. I’ll dive into those in future post.
To actually execute the infrastructure build, I’m using a tool called Terraform.
Terraform does an incredible job of abstracting away all the details you normally have to worry about when provisioning cloud provider infrastructure. It’s a joy to work with. The documentation and examples are easy to follow, and the error messages tell you exactly what you did wrong and where to look.
Terraform Description file example
If that wasn’t cool enough, the Terraform binary is actually built in to the Azure Cloud shell. The net of that is, once you have your deployment files built, you can work with them using just cloudshell, which is super convenient.
Azure Cloud Shell – Checking the Terraform Version
That’s it for today. Lot’s of neat stuff in this lab that I’m dying to talk about, can’t wait to share.
Today we’re going to talk about managing skillsets over time to give oneself the best chance of long term career success and contentment.
Pi shaped skillset: Sun and lighthouse
Introduction
In a perfect world we would all be geniuses with photographic memories and could maintain the maximum attained level of skill for anything we trained for. Sadly this is not how it works for 99.99 percent of the population. It takes time and effort to develop skill, and when we stop doing that thing, skill deteriorates, memory fades.
What’s more, we now live in the age of digital transformation, a time of rapid change and upheaval. There is a good chance that the job you are doing today will not exist in 20 years.
When we combine the perishability of knowledge and skills with a rapidly evolving workplace, it’s self evident that it would be wise to implement some sort of strategy. I have come across several, which I will cover in the following paragraphs. Let’s start with the one everyone knows: T shaped Skillset.
T Shaped Skillset
T-shape skillset example
The T is the classic skillset mix that’s been promoted for a very long time. It’s based on the notion of developing deep expertise in one discipline, with a set of supporting skills around it. This was a very successful industrial age strategy and what a typical university education is designed to produce.
The fundamental problem with the T is it’s very risky in the current day and age. To use an old analogy, if you’re an expert in making buggy whips and people start buying cars, you’re going to have to reskill, and that takes time. You’re going to have a lot of downtime of not making much money while the reskilling is occurring. Been there, done that, not the best strategy for today.
The obvious solution is to have a plan B. Which brings us to the next strategy.
Pi Shaped Skillset
Pi shaped skillset
With a Pi shaped skillet, you cultivate a secondary skillset alongside the primary skillset you use in your day job. Second Skilling is a way to ramp up on emerging or disruptive technology without the income and career impact of reskilling. Additionally it also has the benefit of some cross-pollination, where deeply learned skills can be used across knowledge domains.
There is a third common strategy which typically seen with self employed and business owners/entrepreneurs, which we will cover next.
Skill Stacking
Skill stacking
Skill stackers take a number of skills and combine them to good effect. You don’t have to be particularly great at any of them, but you know how to combine them to produce results. Skill stackers tend to be independent consultants, business owners, inventors, and entrepreneurs.
Skill stacking leverages the concept of the Pareto Principle, which states that approximately 80% of results come from 20% of effort.
In his 2011 book Outliers, Malcolm Gladwell popularized the ten thousand hour rule, which roughly translates to the idea that it takes about 10,000 hours of practice to master something.
If we combine these two ideas of the Pareto Principle and the 10,000 hour rule, we come up with the idea that if we invest approximately 2000 hours of effort in learning and practicing something, we’re getting some real efficiency out of our time, which enables us to have a broader and deeper skillset than we might otherwise be capable of.
Broadening and Creativity
One thing I have observed, is that broadening your horizons and learning a little about a lot of things, particularly in the arts, can beneficial on a number of levels. For example, Nobel prize winning Scientists are 2.85 times more likely to engage in arts and crafts than their counterparts.
Closing thoughts
Anya really wants some fish. If only she had opposable digits and a fishing pole
We live in a world where to stay relevant professionally, we have to be agile; always preparing ourselves for the next opportunity. It’s exciting and frightening at the same time. Having a strategy to stay in position to take advantage of new opportunities is really important. I hope you enjoyed the read, and I’ll see you around.
In PKIFNE part 10 (link), I introduced Cisco IOS Certification Authority, reviewing its use cases, deployment options, and enrollment challenges. In this installment we’re going to dip our toes in the water and put together a basic working configuration utilizing Simple Certificate Enrollment Protocol (SCEP). This design is suitable for production deployment in a small to medium sized network.
Notes:
There are some interactive steps in turning up a CA and enrolling spokes. Also there is a one line configuration difference between a spoke and a hub. for these reasons, the configurations are broken up into several snippets. After the snippets I’ll show you what the output should approximately look like, and we’ll follow that up with some verification commands for testing and troubleshooting your deployment.
In this example, we’re going to do a spoke and hub network, with a CA sitting behind the hub. For simplicity’s sake, I’ll forgo some of the things I would normally include in this kind of design (such as DMVPN with FVRF) so we can focus on the PKI part. Just know that this design is intended to work with a spoke and hub vpn topology.
Demonstration Topology
Quick verification that our toplogy is functional and we have the routes:
Verification from r5
Root CA
Overview
In this simple design we have a single root issuing CA. Let’s go ahead and pop in a somewhat minimal working config. We’re going to:
Generate a 2048 bit RSA keypair called CA
create a folder to hold our pki database
Create a CA server called CA
set the database level to name
set lifetimes on our CA and client certificates (feel free to alter as needed)
set the issuing CA information
Automatically grant certificates
enable the ios HTTP server
Disable all HTTP modules except for the SCEP server
Put an access control list on the HTTP server
CA configuration snippet 1
!------Basic IOS CA-----------!
Crypto key generate rsa modulus 2048 label CA
!
!**** leave blank line after pki*****
do mkdir pki
pki
!
!
ip http server
!
!*****Whitelist for SCEP clients*****
access-list 99 permit 10.1.1.1
access-list 99 permit 10.1.1.2
access-list 99 permit 10.1.1.3
access-list 99 permit 10.1.1.4
access-list 99 permit 10.1.1.5
!
ip http access-class 99
!
crypto pki server CA
Database url flash:/pki/
Database level names
Lifetime ca-certificate 7000
Lifetime certificate 3500
issuer-name cn=r1.densemode.com,O=Densemode,OU=IT
!
!***Grant auto should be combined with http acl to restrict access***
grant auto
!
!*****you will need to interactively enter a passphrase****
!*****After no shut command is issued*****
no shut
This approximately what you should expect to see when turning up the CA:
CA configuration Snippet 2
!——————Disable unused http session modules—————!
ip http secure-active-session-modules none
ip http session-module-list RA SCEP
ip http active-session-modules RA
Client configuration
Overview
The basic workflow is pretty straightforward.
Configure a trust point
Authenticate the CA
Enroll the device with the CA
These are the features we’re going to configure on the client:
!----—router enrollment config-----------!
!*****This goes on the client routers in your topology*******!
!*****Be sure to change the subject-name and fqdn fields*****!
!*****To match your devices*******
!*****Ansible+jinja2 templates would be a great way******
!*****To template this configuration**********
!
Crypto key generate rsa modulus 2048 label CA
!
crypto pki trustpoint CA
Enrollment url http://10.1.1.1
source interface lo0
subject-name cn=r2.densemode.com,O=Densemode,OU=IT
Fqdn r2.densemode.com
Rsakeypair CA
!
!******Accept the CA certificate*****
Crypto pki authenticate CA
you’ll get a prompt asking you to verify you trust the fingerprint of the CA certificate:
Client configuration snippet 2
!******Follow the onscreen prompts****
Crypto pki enroll CA
There will be a short series of prompts prior to the enrollment request being sent to the CA. If everything is in order you get a success notification a few seconds after the request is sent out.
Client configuration snippet 3
!***** Use this on remote spokes to solve CA chicken and egg *****
!***** Reachability problem *****
!***** It's not a security risk because the hub router *****
!***** Will perform the validity checks *******
!
crypto pki trustpoint CA
revocation-check none
Verification of CA
Verification commands:
show crypto pki server
show crypto pki certificates verbose
show ip http server session-module
show ip http server status
show access-list
Our Certification Authority is up and running
Using the ‘show pki server‘ command We can see here that our CA is up and running, along with operational and configuration information.
CA Certificate
The ‘show crypto pki certificates verbose‘ command allows us to inspect the CA server certificate. Notice the certificate usage is signature. This certificate will be used to digitally sign all certificates issued by the CA
http server module status
‘show ip http server session-module‘ can be used to verify we’re only running the minimum services needed for the CA to act as a SCEP server to issue certificates in-band over the network
show ip http server status
This truncated output ‘show ip http server status’ Allows us to verify the access list devices that are allowed to communicate with the SCEP server. In this case it’s access list 99.
http access list example
As we can see here, our access list allows only the loopback interfaces of our routers to request certificates from the CA. For a production network this is vital if you’re going to configure the CA to automatically grant certificates.
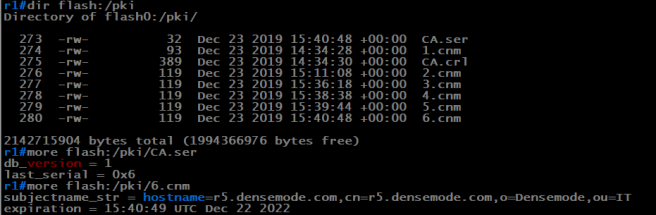
Exploring the contents of the CA database
contents of the pki database
In our sample configuration, we placed the CA database under a folder called PKI. As you can see from the output, there is a:
Serial number file
Certificate Revocation List (CRL)
A file for each certificate issued with the serial # as the filename.
Since we did a database level of name, the serial number file contains the hostname and expiration date of the issued certificate. If you needed to revoke a certificate for a device, this is how you would verify you’re revoking the correct certificate. It’s also why we set the database level to name. 🙂
Client Verification
show crypto pki trustpoint status
show crypto pki certificates verbose
show run | section crypto pki trustpoint
Verifying trustpoint status
The command ‘show crypto pki trustpoint status’ allows to verify that the Trustpoint is properly configured and we have a certificate issued from the CA. We can also inspect the fingerprint of the CA certificate and the router certificate.
Viewing a router certificate in verbose mode
‘Show crypto pki certificates verbose’ allows us to inspect our router certificate in detail. This is an easy way to check the validity period of your certificate and verify that you used a suitably strong keypair in your certificate request.
Trustpoint configuration
‘show run | s crypto pki trustpoint‘ Enables us to check a couple of important details the other commands can’t give us. The important ones among these are:
source interface
revocation-check
Source Interface
Because we’re setting an Access Control List (ACL) on the web server of our issuing CA, it’s important to source the packets from the IP Address that’s in that access list. If we don’t explicitly set the interface, the router will use the routing table to decide which ip address to use.
Revocation Check
In many common designs, the router will not have reachability to the CA until its vpn tunnels come up. However if certificate authentication is being used to form the tunnel, by default the router will attempt to use SCEP to request the Certificate Revocation list (CRL), and the revocation check will fail. We have a chicken and egg problem
Certificate Auth VPN and revocation checks
The solution is straightforward. Since all spokes must transit the hub router to reach the CA, we can have the hub router perform revocation checks and disable it on the spokes. In this way, you can revoke a certificate for a spoke and will be effective as the hub will no longer accept connections from it, preventing the revoked device from coming up on the network.
When we’re inspecting a spoke, we want to see ‘revocation-check none’ in the configuration output.
Revoking a certificate
One of the useful features of IOS CA and PKI in general is we can revoke a certificate at will. For VPN applications this is much better than pre shared keys. In the following exmample, let’s imagine that R5 is being decommissioned.
Checking the serial # on the router
using ‘show crypto pki cerfificate’ on router 5, we can see that the serial number of the certificate is 7. Let’s verify this on the CA.
Verifying the serial # on the CA
using the more command, we can view the contents of certificate serial #7 in the CA database.
Let’s go ahead and revoke the certificate
Revoking a certificate
we revoked the certificate using cry pki server <ca name> revoke <serial #>. This will cause the crl file to be updated so enrolled devices with revocation checking will stop accepting the certificate.
Wrap up
There you have it, a basic utilitarian IOS CA configuration. There are a lot of details left out such as auto-renewal, whether or not to make the private key of the CA exportable for DR purposes, etc. But this is a good 80% solution in my opinion.
Hope you found this useful and I’ll see you around.
In this post we’re going to do a brief overview of Containers and Kubernetes. My aim here is to set the stage for further exploration and to give a quick back of the napkin understanding of why they’re insanely great.
From the earliest days of computers that had multitasking operating systems applications have been hosted directly on top of the host operating system. The process of deploying, testing and updating applications was slow and cumbersome to say the least. The result: mounting technical debt that eventually consumes more and more resources just to keep legacy applications operating, without any ability to update or augment them.
Virtualized Deployment
Virtualization enabled multiple copies of a virtual computer on top of a physical computer. This dramatically improved the efficiently of resource utilization and the speed at which new workloads could be instantiated. It also made it convenient to run a single application or service per machine.
Because of the ease in which new workloads could be deployed, In this era we started to see horizontal scaling of applications as opposed to vertical scaling. This means running multiple copies of a thing and placing the copies behind a load balancer, as opposed to making the things bigger and heavier. This is an example of how introducing a new layer of abstraction results in innovation, which is a hallmark of the history of computers.
However, Some problems emerged with the explosion of virtualized distributed systems. Horizontal scaling techniques add additional layers of complexity, which made deployments slower and more error prone. Operations issues also emerged due to the need to monitor patch and secure these growing fleets of virtual machines. It was two steps forward, one step backward.
Container deployment
Containers are a similar concept to Virtual machines, however the isolation occurs at the operating system level rather than the machine level. There is a single host operating system, and each application runs in isolation.
Containers are substantially smaller and start almost instantly. This allows for containers to be stored in a central repository where they can be pulled down and executed on demand. This new abstraction resulted in the innovation of immutable infrastructure. Immutable infrastructure solves the day 2 operations of care and feeding of the running workloads. However it doesn’t solve for the complexity of deploying the horizontal scaling infrastructure. This is where Kubernetes comes in.
Kubernetes: Container orchestrator
Kubernetes is a collection of components that:
Deploys tightly coupled containers (pods) across the nodes
Scales the number of pods up and down as needed
Provides load balancing (ClusterIP, Ingress controller) to the pods
Defines who the pods can communicate with
Gives pods a way to discover each other
Monitors the health of pods and services
Automatically terminates and replaces unhealthy pods
Gracefully rolls out new versions of a pod
Gracefully rolls back failed deployments
Kubernetes takes an entire distributed application deployment and turns it into an abstraction that is defined in YAML files that can be stored in a version control repository. A single K8s cluster can scale to hundreds of thousands of Pods on thousands of nodes. This abstraction has resulted in an explosion of new design patterns that is changing how software is written and architected, and has led to the rise of Microservices. We’ll cover Microservices in another post.
I hope this was helpful and gave you a useful concept of what Kubernetes is and why it’s such a game changer. Would you like to see more diagrams? Let me know your thoughts.
I took this photo just a few minutes ago on my Monday morning beach walk. I hope you find it relaxing.
Holy cow, been 8 months since my last dispatch. Still studying and learning cool stuff, have not done a good job at stopping to document my learnings, going to make another attempt to rectify that.
Been an eventful year. In addition to learning DevOps tools and techniques and studying cloud native software design, I’ve also changed jobs. As of August I’ve been working at Cisco systems as a pre-sales Architect. It’s a dream job and I absolutely love working with my customers. I learn as much from them as they learn from me.
So yeah, the new job thing; several months of getting the firehose and struggling to take everything in and find my stride.
I didn’t feel like that was enough new stuff, so I enrolled in WGU’s Cybersecurity Bachelor’s program starting in January. I don’t **need** a degree, but I don’t think it would hurt to become a more well-rounded technologist. I’ve historically used certifications for learning paths which is fine but they tend to be narrowly defined in scope which can lead to polarized thinking.
So here’s the plan for the blog: I’m committing to posting something every Monday morning, even if it’s just a “hello, I’m drinking coffee and checking my twitter feed how about you”. I have a sizable collection of study notes, so there’s no shortage of meaningful topics however. Hopefully I’ll dip into that more than the small talk :).
Have a great week, talk to you next Monday morning.
In the next few PKI for network engineers posts, I’m going to cover Cisco IOS CA. If you’re studying for the CCIE security lab or you’re operating a DMVPN or FlexVPN network, and you’d like to use Digital certificates for authentication, then this series could be very useful for you.
Introduction
IOS-CA is the Certification Authority that is built into Cisco IOS. While not a full featured enterprise PKI, for the purposes of issuing certificates to routers and firewalls for authenticating VPN connections it’s a fine solution. It’s very easy to configure and supports a variety of deployment options.
Key points
Comes with Cisco IOS
Supports enrollment over SCEP (Simple Certificate Enrollment Protocol)
RSA based certificates only
Easy to configure
Network team maintains control over the CA
Solution can scale from tiny to very large networks
Deployment Options
IOS-CA has the flexibility to support a wide variety of designs and requirements. The main factors to consider are the size of the network, what kind of transport is involved, how the network is dispersed geographically, and the security needs of the organization. Let’s briefly touch on a few common scenarios to explore the options.
Single issuing Root CA
For a smaller network with a single datacenter or a active/passive datacenter design, a single issuing root may make the most sense. It’s the most basic configuration and it’s easy to administer.
This solution would be appropriate when the sole purpose of the CA is to issue certificates for the purpose of authenticating VPN tunnels for a smaller network of approximately a hundred routers or less. Depending on the precautions taken and the amount of instrumentation on the network, the blast radius of this CA compromise would be relatively small and you could spin up a new CA an enroll the routers to it fairly quickly.
The primary consideration for this option is CA placement. A good choice would be a virtual machine on a protected network with access control lists limiting who can attempt to enroll. The CA is relatively safe from being probed and scanned, and it’s easily backed up.
Fig 1. Single issuing root
Offline Root plus Issuing Subordinate CAs
For a network that has multiple datacenters and/or across multiple continents it would make more sense to create a Root CA, then place a subordinate Issuing CA each datacenter that contains VPN hubs. By Default IOS trusts a subordinate CA, meaning the root CA’s certificate and CRL need not be made available to the endpoints to prevent chaining failure.
As in the case with any online/Issuing CA, steps should be taken to use access controls to limit access to HTTP/SCEP
Fig 2. Offline Root
Issuing Root with Registration Authority
Fig 3. Single root with Registration authority
In this design, there is still a single issuing root, however the enrollment requests are handled by an RA (Registration Authority). An RA acts as a proxy between the CA and the endpoint. This allows for the CA to have strict access controls yet still be able to process enrollment requests and CRL downloads.
Offline Root & Issuing Subordinate CAs w/RA
The final variation is a multi-level PKI that uses the RA to process enrollment and CRL downloads. This design provides the best combination of security, scaling, and flexibility, but it is also the most complex.
Bootstrapping remote routers
Consider a situation where you’re turning up a remote router and you need to bring up your transport tunnel to the Datacenter. The Certification authority lives in the Datacenter on a limited access network behind a firewall. In order for the remote router to enroll in-band using SCEP, it would need a VPN connection. But our VPN uses digital certificates.
There are three options for solving this:
Sideband tunnel w/pre-shared key
This method involves setting up a separate VPN tunnel that uses a pre-shared key in order to provide connectivity for enrollment. This could be a temporary tunnel that’s removed when enrollment is complete, or it could be shut down and left in place for use at a later time for other management tasks.
A sideband tunnel for performing management tasks that may bring down the production tunnel(s) is useful, making this a good option. It’s main drawback is the amount of configuration work required on the remote router. It also depends on some expertise on the part of the installer, a shortcoming shared with the manual enrollment method.
Registration Authority
A Registration Authority is a proxy that relays requests between the Certification Authority and the device requesting enrollment. In this method an RA is enabled on the untrusted network for long enough to process the enrollment request. Once the remote router has been enrolled the the transport tunnels will come up and bootstrapping is complete.
Using a proxy allows in-band enrollment with a minimum amount of configuration on the remote router, making it less burdensome for the on-site field technician. The tradeoff is we’re shifting some of that work to the head end. Because the hub site staff is likely to possess more expertise, this is an attractive trade-off.
Manual/Terminal enrollment
In this method, the endpoint produces a Enrollment request on the terminal formatted as base64 PEM (Privacy Encrypted Mail) Blob. The text is copied and pasted into the terminal of the CA. The CA processes the request and outputs the certificate as a PEM file, which is then pasted into the terminal of the Client router.
While this does have the advantage of not requiring network connectivity between the CA and the enrolling router, it does have a couple of drawbacks. Besides being labor intensive and not straightforward for a field technician to work with, endpoints enrolled with the terminal method cannot use the auto-rollover feature, which allows the routers to renew certificates automatically prior to expiration. The author regards this is an option of last resort.
CRL download on spokes problem
The issue here is when the spoke router needs to download the certificate revocation list (CRL) but the CA that has the CRL is reachable only over a VPN tunnel, that cannot come up because the spoke can’t talk to the CA to download a unexpired copy of the CRL in order to validate the certificate of the head end router.
This is actually a pretty easy problem to solve. Disable CRL checking on the spoke routers, but leave it enabled on the hub routers. This way the administrator can revoke a router certificate and that router will not be allowed to join the network because the hub router will see that it’s certificate has been revoked.
Wrap-up
Ok, so there are the basics. In the next installment, we’ll step through a minimum working configuration.
So, I’m committed to the study of coding in python for 250 hours a year. And I’m about 12 weeks in.
I have no ambitions of becoming a professional developer. I like being an infrastructure guy. So why in the heck am I making this commitment as part of my professional development?
Here’s a fundamental problem infrastructure designers & engineers of all stripes are faced with today:
The architecture, complexity, and feature velocity of modern applications overwhelms traditional infrastructure service models. The longer we wait to face this head on, the larger the technical debt will grow, and worse, we become a liability to the businesses that depend on us.
Allow me to briefly put some context around this. I’m going use some loose terminology and keep things simple and high level so we can quickly set the stage. Then I’ll explain where python fits in.
Application Components
Most all software applications have three major components:
data store
data processing
user (or application) interface
Overall, the differences in complexity come down to component placement and whether or not each function supports multiple instances for scaling and availability.
Application Architectures
A stage 1 or basic client/server application will place all components on a single host. Users access the application using some sort of lightweight client or terminal that provides input/ouput and display operations. If you buy something at Home Depot and glance at the point of sale terminal behind the checkout person, you’re probably looking at this kind of app.
A stage 2 Client/server application will have a database back end, with the processing and user interface running as a monolithic binary running on the user’s computer. This is the bread and butter of custom small business applications. Classic example of this would the program you see the receptionist using at a doctor or dentist’s office when they’re scheduling your next appointment. Suprisingly, this design pattern is still commonly used to develop new applications even today, becuase it’s simple and easy to build.
A stage 3 Client/Server application splits the 3 major components up so that they can run on different compute instances. Each layer can scale independently of the other. In older designs, the user interface is a binary that runs on the end user’s computer. Newer designs used web based user interfaces. These tend to be applications with scaling requirements in the hundreds to tens of thousand of concurrent sessions. These apps tend to be constrained by the database design. A typical SQL database is single master and often the choke point of the app. There are many of examples in manufacturing and ERP systems of 3 layer designs where the ui and data processing is scale-out, backed by a monster SQL Server failover cluster .
All of these design patterns are based on the presumption of fixed, always available compute resources underpinning them. They’re also generally vendor centric technology stacks with long life cycles. They all depend on redundancy underpinning the compute storage and network components for resiliency, with the 3 tier being the most robust as 2 of the layers can tolerate failures and maintain service.
Traditional infrastructure service models are built around supporting these types of application designs and it works just fine.
Then came cloud computing, and the game changed.
Stage 4: Cloud native applications.
Cloud native applications operate as an elastic confederation of resilient services. Let’s unpack that.
Elastic means service instances spin up or down dynamically based upon demand. when an instance has no work to do, it’s destroyed. When additional capacity is required, new instances are dynamically instantiated to accommodate demand
Resilient means the individual services instances can fail and the application will continue running by simply destroying the failed service instance and instantiating a healthy replacement.
Confederation means a collection of services are designed to be callable via discoverable APIs. This means if an application needs a given function that can be offered by an existing service, the developer can simply have his application consume it. This means components of an application can live anywhere, as long as they’re reachable and discoverable over the network.
Because of this modular design, it’s easy to quickly iterate software, adding additional functions and features to make it more valuable to it’s users.
Great! but as an infrastructure person how do we support something like this? The fact is, this is where traditional vendor-centric shrink wrap tool approach breaks down.
Infrastructure delivery and support
Here are the main problems with shrink wrap monolithic tools in context of cloud native application design patterns:
Tool sprawl (ever more tools and interfaces to get tasks done)
Feature velocity quickly renders tool out of date
Graphical tools surface a small subset of a product’s capabilities
Difficult to automate/orchestrate/manage across technology domains
Figure 1 is what the simple task of instantiating a workload looks like on 4 different public cloud providers. Project this sprawl across all the componentry required to turn up an application instance and the scope of the problem starts to come into focus.
Fig 1: Creating a virtual machine on different cloud providers.
So how in the heck do you deal with this? The answer is surprisingly simple: infrastructure tools that mirror the applications the infrastructure needs to support.
TL;DR Learn how to use cloud native tools and toolchains. And this brings us to the title of the blog post.
Python as a baseline competency
Python is the glue that lets you assemble your own collection of services in a way that’s easy for your organization’s developers and support people to consume. The better you are with python, the easier it is to consume new tools and create tool chains. Imagine that you’re at a restaurant and you’re trying to order for yourself and your family. If you can communicate fluently, it’s much easier to get what you want than if you don’t speak the language, and are reduced to pointing at pictures and pantomiming.
Interestingly, I’ve found that many of the principles of good network and systems design are directly applicable to writing a good program. encapsulation, separation, information hiding, discreet building blocks, etc.
Use Case: Creating a Virtual Machine
Let’s take the example of creating a virtual machine.
For creating a VM, we could create a class or classes in python that allows someone to spin up, shut down and check the status of virtual machines on 4 different public cloud providers in a manner that abstracts the specifics of each provider and gives them to the user as a generic service. Then we or anyone else on the team can use it to spin up workloads with a simple call, without having to know the implementation details of each provider.
The power of making tools like this is:
we only have to solve the problem of doing a thing once
we encapsulate it
we make it available to other code
In the next installment of my DevOps journey, I’ll take a stab at writing the python Virtual Machine class described and we’ll see how well it works.